파이썬 무신사 이미지 크롤링 다운로드 셀레니움, BeautifulSoup, requests
파이썬 셀레니움과 requests, BeautifulSoup 등을 사용하여 웹페이지에 있는 이미지를 다운로드할 수 있습니다. 두 가지 방법에 대해서 소개를 해볼 건데 첫 번째는 셀레니움과 requests를 사용한 이미지 다운로드입니다. 그전에 무신사 사이트의 구조에 대해서 먼저 알아볼 필요가 있습니다.
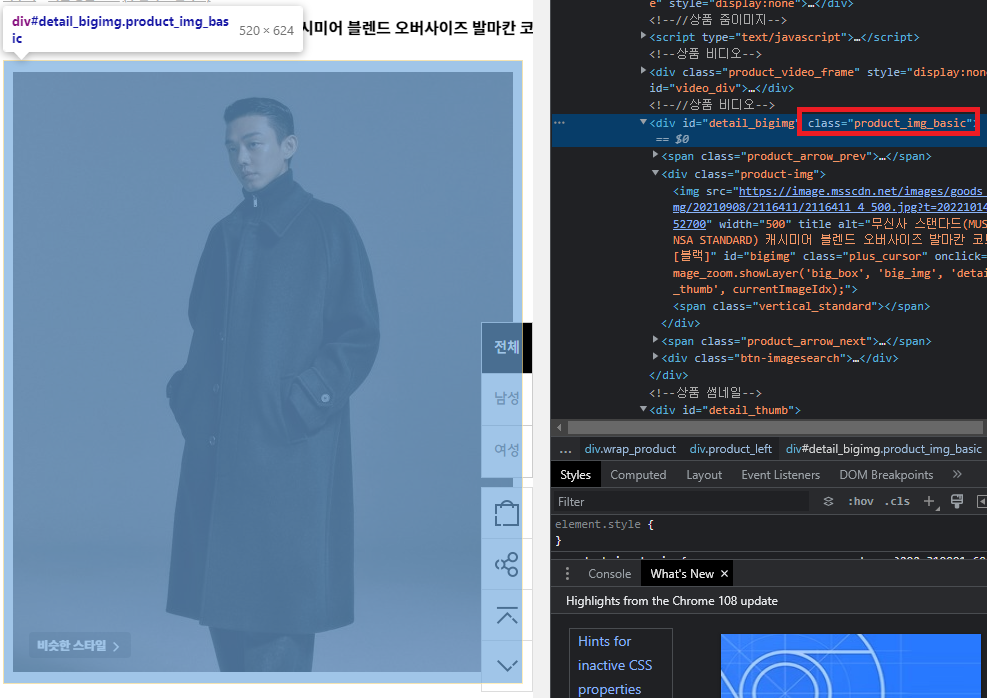
먼저 무신사 사이트에서 메인 이미지가 보여지는 위치는 클래스 product_img_basic 내부에 있습니다. 코드를 작성할 때 첫 번째로 해당 클래스가 존재하는지 여부를 파악하고 오류를 방지할 수 있습니다.
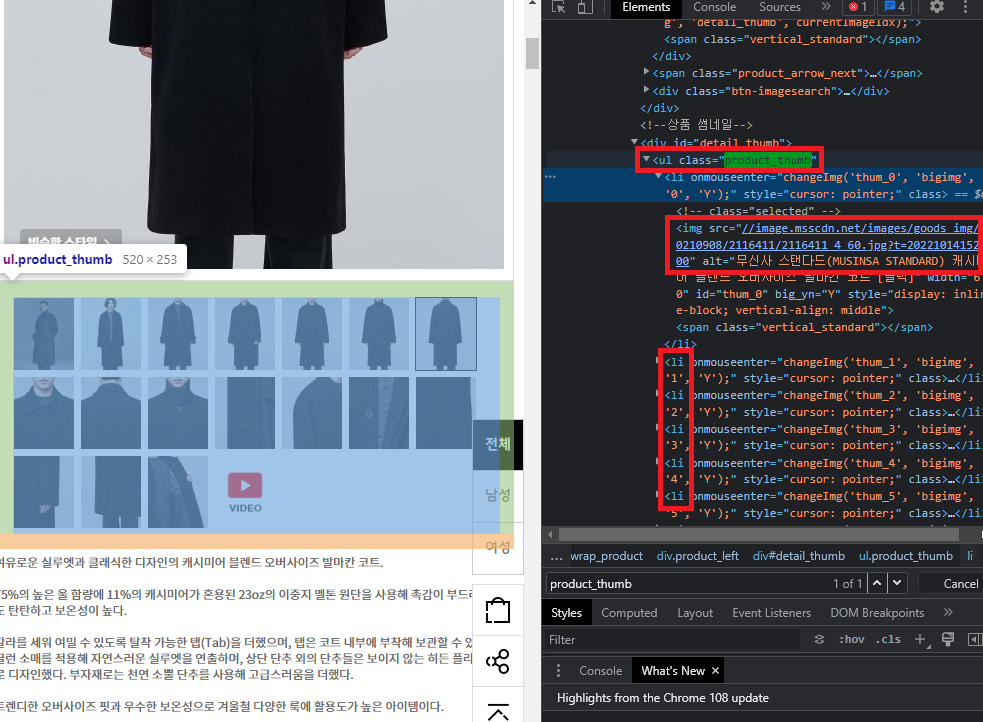
그리고 여러장의 이미지는 그 하단 product_thumb 클래스에 li 형태로 위치하는 것을 볼 수 있습니다. 거기서 img 태그의 src를 보면 이미지 고유 주소를 파악할 수 있습니다. 이제 이 고유 주소를 가져와서 requests 모듈의 기능을 사용하여 이미지 다운로드를 시도할 수 있습니다.

img 태그에 들어가 있는 src의 값은 픽셀 값이 60으로 그대로 다운로드를 시도하면 이미지가 작게 출력이 됩니다. 해당 값은 최대 500까지 늘릴 수 있기 때문에 코드를 작성할 때 픽셀 값 부분만 replace로 변경하는 방법을 사용했습니다.
1. 셀레니움 + requests 사용하기
from selenium import webdriver
import chromedriver_autoinstaller
import requests
import os
import re
def image_down_multi(image_url_list):
for i_i in range(len(image_url_list)):
keword_image_get = requests.get(image_url_list[i_i])
with open(fr'image/{i_i}_image.jpg', 'wb') as fl_s:
fl_s.write(keword_image_get.content)
print(f'{i_i}_image.jpg 다운로드 완료')
def remove_all_file(file_path):
if os.path.exists(file_path):
for file in os.scandir(file_path):
os.remove(file.path)
return 'Remove All File'
else:
return 'Directory Not Found'
user_agents = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/102.0.5005.63 Safari/537.36'
ver_1 = re.compile(r'(?<=Chrome/).+?(?= )').search(user_agents).group()
ver_2 = chromedriver_autoinstaller.get_chrome_version()
if not ver_1 == ver_2:
user_agents = user_agents.replace(ver_1, ver_2)
path = chromedriver_autoinstaller.install(True)
options = webdriver.ChromeOptions()
options.add_argument(f'user-agent={user_agents}')
options.add_argument('headless') # 백그라운드 작업
options.add_experimental_option("excludeSwitches", ["enable-automation", "enable-logging"])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(path, options=options)
driver.implicitly_wait(5)
print('무신사 이미지 다운로드')
while True:
image_list = []
image_page = input("페이지 입력\n")
if not image_page:
continue
driver.get(image_page)
# 이미지 클래스 체크
if not driver.find_elements_by_class_name('product_img_basic'):
print('이미지 요소를 찾을 수 없음!')
continue
remove_all_file('image') # 폴더 초기화
print('다운로드를 시도합니다')
# img 태그에서 src(이미지 url)를 리스트에 넣기
# 리스트에 넣을 때 이미지 사이즈 변환 (초기값 60px에서 500px로)
prdt_image_tags = driver.find_element_by_class_name('product_thumb').find_elements_by_tag_name('img')
[image_list.append(str(src.get_attribute('src')).replace('60.jpg', '500.jpg')) for src in prdt_image_tags]
# 이미지 다운로드
image_down_multi(image_list)image_down_multi, remove_all_file 두개의 함수를 만들어 놨습니다. 이미지를 다운로드하는 함수와 이미지를 폴더에서 제거하는 함수로 사용이 됩니다. while 반복문이 돌 때마다 기존에 생성했던 이미지는 제거 후 새로운 이미지를 다운로드하는 방식입니다.
[image_list.append(str(src.get_attribute('src')).replace('60.jpg', '500.jpg')) for src in prdt_image_tags]for 반복문을 한 줄 처리로 작성한 형태인데 이 구간을 가독성 좋게 표시를 한다면 다음과 같습니다.
for src in prdt_image_tags:
src_get = src.get_attribute('src') # img 태그에서 src 가져오기
src_replace = str(src_get).replace('60.jpg', '500.jpg') # 글자 변경
image_list.append(src_replace) # 리스트에 추가코드의 모양은 다르지만 같은 기능이라고 볼 수 있겠네요.
# 이미지 다운로드
image_down_multi(image_list)기존에 만들어둔 함수 매개변수에 리스트를 넣어서 함수를 작동시키면 이미지 다운로드를 시도합니다. 참고로 프로그램이 구동되는 동일 폴더에 image라는 폴더가 생성이 된 상태일 때 오류 없이 프로그램이 작동됩니다.
2. BeautifulSoup + requests 사용하기
셀레니움의 경우 사실 웹을 직접 열고 작업을 하는 형태다 보니까 속도가 느릴 수 있습니다. 만약 요청만으로 크롤링이 가능한 경우라면 BeautifulSoup을 사용하는 것이 훨씬 효율적입니다. 코드는 셀레니움에서 BeautifulSoup으로 변경만 한 거라 크게 다를 건 없습니다. 코드는 while True의 반복문 부분만 변경을 했습니다.
추가적으로 BeautifulSoup의 경우 이미지 src를 가져올 때 앞 쪽 http: 부분이 제거된 상태로 가져오기 때문에 문자열을 추가해야합니다.
headers = {'user-agent': user_agents}먼저 요청으로 웹사이트와 소통하기 위해서는 headers에 user-agent를 넣어주고 요청을 시도해야 합니다. 사이트마다 다르지만 보통은 user-agent를 넣어줘야 원활한 소통이 가능합니다. 전체 코드는 아래와 같습니다.
from bs4 import BeautifulSoup
import chromedriver_autoinstaller
import requests
import os
import re
def image_down_multi(image_url_list):
for i_i in range(len(image_url_list)):
keword_image_get = requests.get(image_url_list[i_i])
with open(fr'image/{i_i}_image.jpg', 'wb') as fl_s:
fl_s.write(keword_image_get.content)
print(f'{i_i}_image.jpg 다운로드 완료')
def remove_all_file(file_path):
if os.path.exists(file_path):
for file in os.scandir(file_path):
os.remove(file.path)
return 'Remove All File'
else:
return 'Directory Not Found'
user_agents = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/102.0.5005.63 Safari/537.36'
ver_1 = re.compile(r'(?<=Chrome/).+?(?= )').search(user_agents).group()
ver_2 = chromedriver_autoinstaller.get_chrome_version()
if not ver_1 == ver_2:
user_agents = user_agents.replace(ver_1, ver_2)
headers = {'user-agent': user_agents}
print('무신사 이미지 다운로드')
while True:
image_list = []
image_page = input("페이지 입력\n")
if not image_page:
continue
get_req = requests.get(image_page, timeout=10, headers=headers)
if not get_req.status_code == 200:
print('페이지 접근 오류!')
continue
soup = BeautifulSoup(get_req.text, 'html.parser')
# 이미지 클래스 체크
if not soup.find(class_='product_img_basic'):
print('이미지 요소를 찾을 수 없음!')
continue
remove_all_file('image') # 폴더 초기화
print('다운로드를 시도합니다')
# img 태그에서 src(이미지 url)를 리스트에 넣기
# 리스트에 넣을 때 이미지 사이즈 변환 (초기값 60px에서 500px로)
prdt_image_tags = soup.find(class_='product_thumb').find_all('img')
[image_list.append('http:' + str(src['src']).replace('60.jpg', '500.jpg')) for src in prdt_image_tags]
# 이미지 다운로드
image_down_multi(image_list)while True에서 바뀐 부분은 셀레니움에서 driver로 처리를 하던 코드를 soup으로 변경을 했습니다. 코드를 실행하고 타겟 url을 넣어보면 확실히 셀레니움에 비해서 속도가 빠른 것을 볼 수 있습니다.
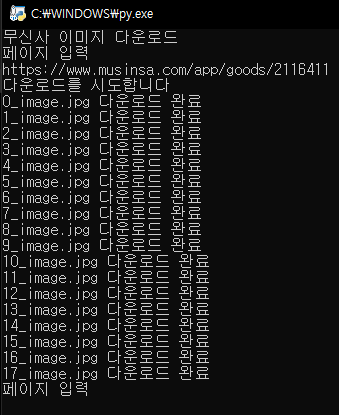
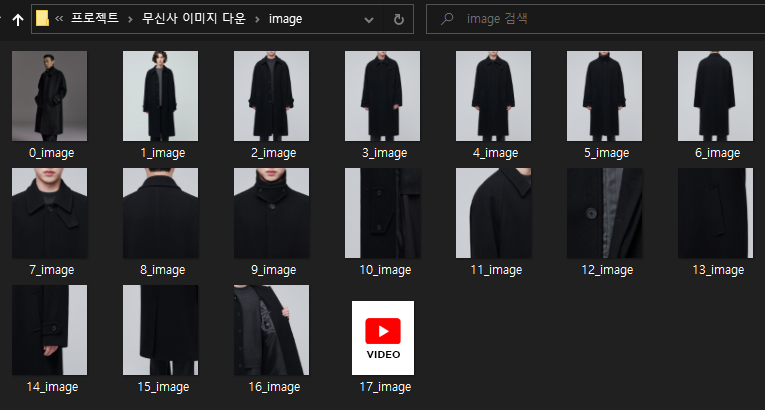
결국 두 방식 모두 이미지를 다운로드하는 것은 동일하기 때문에 image 폴더에 이미지가 저장되는 것을 볼 수 있습니다.
'파이썬 프로그래밍' 카테고리의 다른 글
| 파이썬 gui pyqt5 위젯 소개 및 사용 방법 예제 (0) | 2023.01.02 |
|---|---|
| 파이썬 요청 모듈 requests get, post, header 사용 방법 (0) | 2023.01.02 |
| 파이썬 url 웹사이트 exe 이미지 동영상 파일 다운로드 (Requests) (0) | 2022.12.10 |
| 파이썬 pyqt5 설치 Qt Designer 사용법 및 ui py 파일 변환 (0) | 2022.12.04 |
| 파이썬 셀레니움 Selenium 파일 첨부 업로드 (0) | 2022.11.27 |